Потоки данных
Потоки данных обеспечивают прием, нормализацию и обработку информации в системе Monq.
Ключевые возможности
- Автоматическая нормализация данных при приеме
- Гибкая обработка (встроенные парсеры + кастомные сценарии)
- Специализированное хранение (оптимизированные СУБД для каждого типа данных)
Типизация потоков
Каждый поток имеет строго определенный тип, что задает:
- Доступные форматы данных
- Возможные обработчики
- Правила нормализации
| Тип потока | Обрабатываемые данные | Примеры форматов | Доступные обработчики |
|---|---|---|---|
| События и логи | Текстовые данные (логи, события) | JSON, Nginx, Apache, Syslog | Парсеры, Regex, строковые преобразования |
| Метрики | Числовые временные ряды | Prometheus, OpenTSDB, Zabbix | Встроенные конвертеры метрик |
Важно:
- Обработчики не взаимозаменяемы между типами потоков
- Выбор типа определяет всю дальнейшую цепочку обработки
Характеристики потоков
- Уникальный ID - идентификатор в системе
- API ключ - идентификатор для маршрутизации данных в конкретный поток
- Название и описание - для удобства навигации по потокам
- Тип данных (выбирается при создании):
- События и логи - для текстовых данных
- Метрики - для числовых временных рядов
- Парсер (обработчик) - правило преобразования входящих данных
- Хранилище - куда записываются данные (выбирается автоматически в зависимости от типа)
- Действия после получения (только для событий и логов):
- Только хранение
- Только пост-обработка
- Хранение и пост-обработка
Ручное создание потока данных
Для создания нового потока данных выполните следующие действия:
-
Перейдите в раздел Сбор (ETL) - Потоки данных через основное меню
-
Нажмите кнопку Создать поток в верхнем правом углу
-
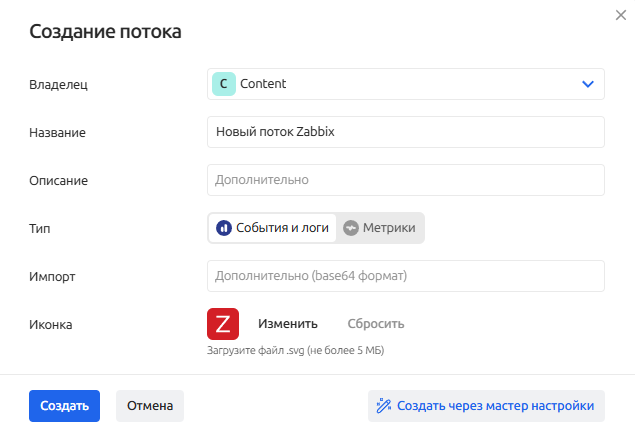
Заполните поля:
- Владелец - Рабочая группа, которой принадлежит поток данных
- Название (уникально в рамках Рабочей группы)
- Описание - опционально
- Тип потока (нельзя изменить после создания)
- События и логи
- Метрики
- Импорт - данные в формате
base64, которые содержат инструкции для создания нового потока с предустановленными настройками (например, экспортированные из другой системы) - Иконка (файл в формате SVG, не более 5 Мб)
-
Нажмите кнопку Создать - откроется страница настройки, добавленного потока данных
-
Дальнейшая настройка потока данных зависит от его типа и требований источника данных.
Перейдите в раздел Интеграции для ознакомления с примерами конфигурации потоков данных под различные источники
Создание потоков данных из мастера настройки
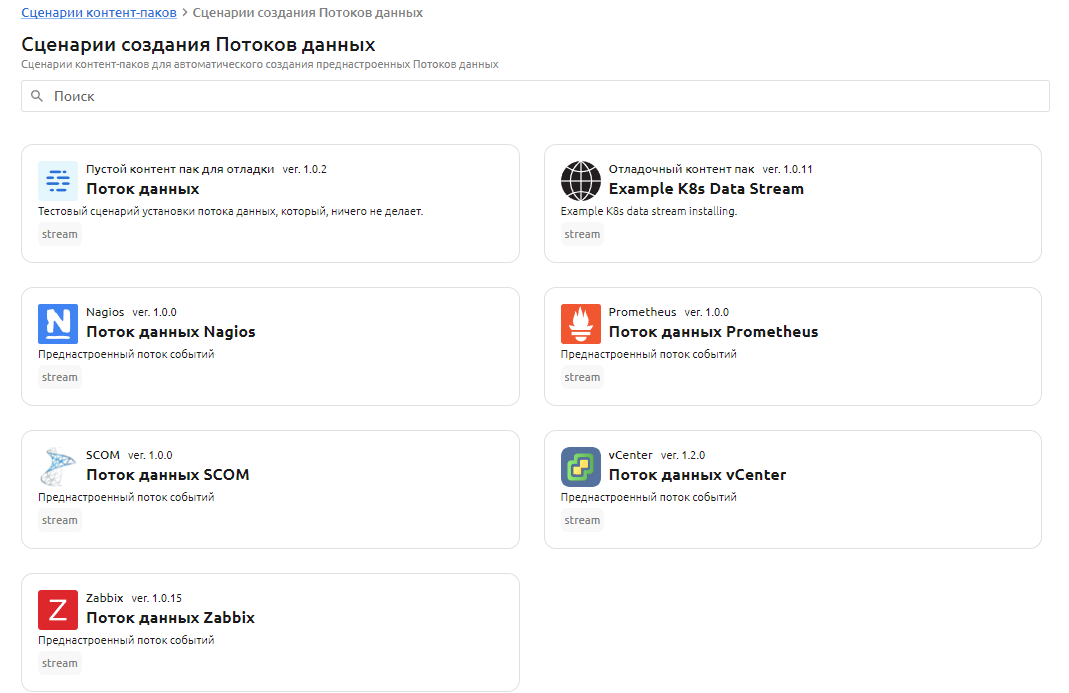
Пользователь может создать заранее подготовленные потоки данных по шаблону (например, Zabbix, vCenter, Prometheus и другие). Каждый шаблон потока - это отдельный контент-пак в Мастере настройки Monq.
В имеющихся в мастере настройки контент-паках уже сконфигурированы различные параметры потоков данных (например, тип, парсер или обработчик, настройки хранения и прочее).
Для некоторых контент-паков, где получение данных осуществляется методом pull - имеются предустановленные сборщики данных.
Чтобы создать поток данных по шаблону из контент-пака:
-
Перейдите в раздел Сбор (ETL) - Потоки данных через основное меню
-
Нажмите кнопку Создать через мастер настройки в верхнем правом углу
-
Выберите из списка нужный вам контент-пак:
-
Ознакомьтесь с содержимым контент-пака на вкладках Обзор
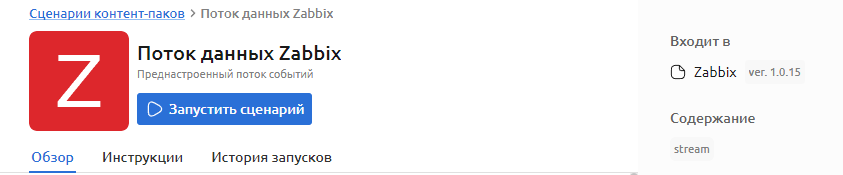
-
Нажмите кнопку Запустить сценарий
-
В открывшейся форме создания потока данных, вы можете опционально задать свое название потока данных, его описание и выбрать РГ владельца потока
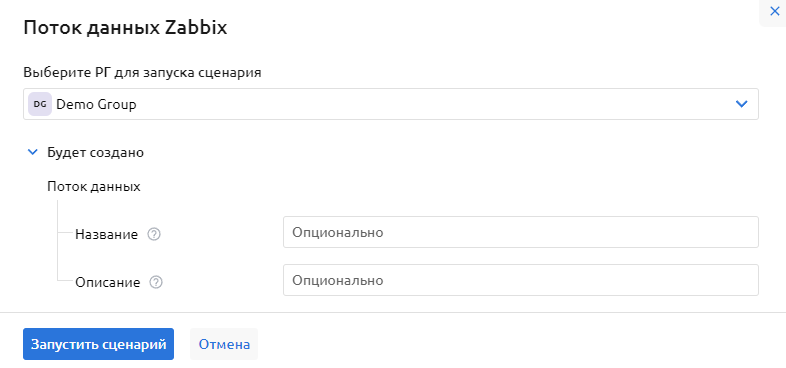
По умолчанию, без указания данных параметров, поток данных будет создан с названием "Zabbix Stream" и описанием "Zabbix Data Stream created by Content Wizard".
Для ряда контент-паков, где требуется извлечение данных из внешних систем, предлагается заполнить параметры подключения:
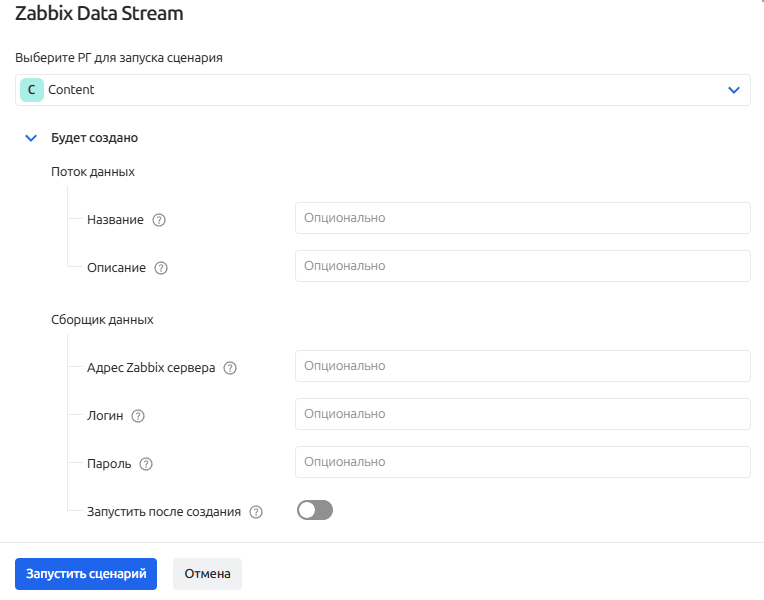
⚠️ Рекомендуем заполнять параметры перед запуском сценария контент-пака. В противном случае потребуется перейти в раздел "Сборщики данных", выбрать нужный сборщик и заполнить параметры вручную. А если сборщиков данных было создано несколько, необходимо повторить процедуру для каждого.
-
Еще раз нажмите кнопку Запустить сценарий в форме создания потока данных
-
На вкладке "История запусков" будет отображаться процесс создания "Потока данных" по выбранному шаблону контент-пака. По завершению создания потока данных будет отображаться инструкция по дальнейшей настройке потока
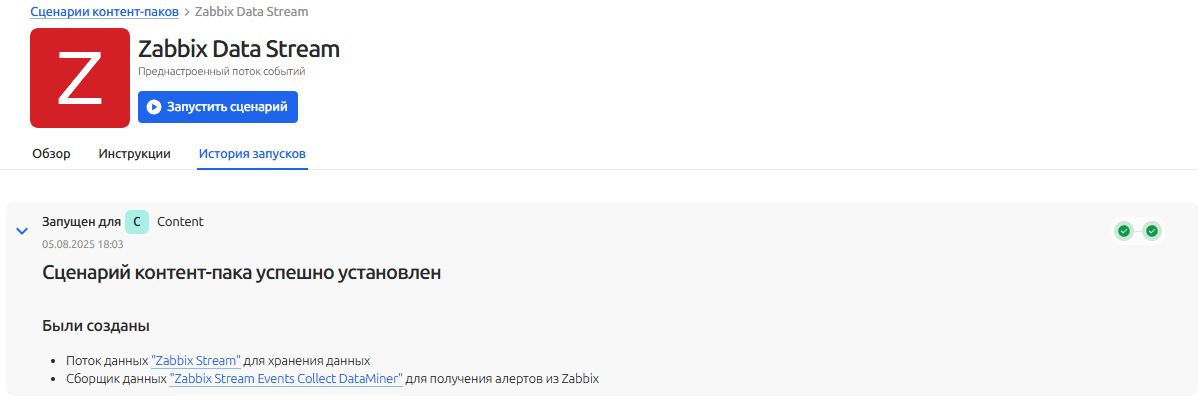
Запуск и остановка потока данных
Возможность временно приостанавливать и возобновлять прием и обработку данных в потоке позволяет:
- Контролировать нагрузку на систему. Остановка неактуальных потоков снижает потребление ресурсов (CPU, память, дисковый I/O). Позволяет избежать перегрузки при пиковой активности или технических работах.
- Безопасное внесение изменений. Перед обновлением конфигурации потока (например, изменением ETL-правил) его можно остановить, чтобы избежать обработки данных в некорректном состоянии.
- Экономия затрат на хранение. Приостановка потоков с низкой ценностью данных (например, тестовых или дублирующих) сокращает объем хранимой информации и затраты на СХД.
Чтобы выполнить остановку или запуск потока данных выполните следующие действия:
- Перейдите в раздел Сбор (ETL) - Потоки данных через основное меню системы
- Найдите необходимый поток данных
- Воспользуйтесь переключателем состояния потока или вспомогательным меню ︙ для запуска/остановки соответствующего потока данных
Запустить или остановить поток данных, также, можно со страницы настроек этого потока:
- Перейдите на страницу настройки потока
- В правом верхнем углу нажмите Запустить/Остановить поток
Блокировка потока данных
Если в настройках пространства установлены правила блокировки потоков и такое правило сработало - в общем списке потоков и в карточке заблокированного отображается соответствующее сообщение.

Настройка потока данных
Для настройки потока данных, перейдите в карточку потока данных, который нужно настроить.
Изменение основной информации
В блоке «Основная информация» пользователь может посмотреть или изменить следующие параметры потока:
- Владелец
*при условии, что поток не используется ни в одном индексе - Название
- Описание
- Иконка
Получение данных
Для того чтобы отправить данные в поток вам понадобится API ключ, при помощи которого идентифицируются отправляемые данные в поток. Также перед отправкой необходимо убедиться, что поток включен.
Для потоков данных с типом события и логи в интерфейсе доступен готовый Webhook URL, который содержит готовый путь для отправки Webhook из внешних систем в формате:
{URL пространства}/api/public/cl/v1/stream-data?streamKey={API ключ потока}
Например: https://demo.example.ru/api/public/cl/v1/stream-data?streamKey=3160a64c-2fdd-43e6-b77f-50e904072024
Пред-обработка данных
Для потоков данных с типом "События и логи" пользователю доступен набор обработчиков (парсеров) под различные форматы поступающих данных. Обработчики нормализуют сырые входящие данные по заданным правилам в формат Monq. С полным перечнем обработчиков можно ознакомиться в разделе Обработчики.
Исключением из списка является обработчик - Automaton. При выборе которого, пользователю становиться доступным, написание собственных обработчиков для входящих потоков данных при помощи сценариев автоматизации на low-code.
Для редактирования обработчика Automaton перейдите по ссылке "Перейти к сценарию", чтобы открыть сценарию обработки данных.

⚠️ Переход к редактированию сценария обработчика
Automatonвозможен только со страницы конфигурации Потока данных.
Подробная информация по работе со сценариями визуального движка программирования содержится в разделе Автоматизация.
Активация/деактивация обработчика Automaton
Активация или деактивация сценария обработчика синхронизирована с состоянием Потока данных.
Деактивировать сценарий можно отключив Поток данных. Активация сценария производится аналогично.
Сброс настроек обработчика Automaton
Если сценарий обработчика невозможно исправить или его поведение стало нестабильным, вы можете выполнить сброс "к настройкам по умолчанию". В этом режиме обработчик Automaton автоматически:
- Проверяет корректность структуры входящих данных
- Приводит события к стандартизированному формату
Этот режим гарантирует минимальную работоспособность потока.
Хранение данных
В целях экономии дискового пространства СХД, можно настроить время хранения событий для выбранного потока данных.

По умолчанию, для всех создаваемых потоков данных устанавливается время хранения "согласно настройкам пространства". Подробнее о настройках пространства.
Кроме того, время хранения событий можно задать кратным 1 дню.
При включении данной настройки для потоков, которые содержат события с даты не вошедшей в интервал хранения, пользователь получит сообщение:
с возможностью подтвердить или отменить данное действие.
Для настройки периода хранения данных в потоке:
- Перейдите на вкладку "Настройки" необходимого потока данных
- В блоке "Хранилище" выберите из списка параметр "в течении"
- Укажите количество дней, сколько хранить события
- Нажмите "Сохранить изменения"
Настройка глубины хранения данных, установленная в конкретном потоке, имеет меньший приоритет, чем та же настройка на уровне пространства.
Таким образом, если в потоке установлено хранение данных в течение 30 дней, а в настройках пространства в течение 7 дней - данные будут удалены через 7 дней.
Пост-обработка данных
После получения событий, как уже упоминалось ранее, их можно:
- Только хранить
- Только обрабатывать
- И хранить И обрабатывать
Пост-обработка данных подразумевает, что полученное событие будет отправлено в модуль автоматизации (сценарии автоматизации или бизнес-процессы) для дальнейшей обработки (создание инцидентов, наполнение CMDB и прочее).
Для включения пост-обработки событий в потоке:
- Перейдите на вкладку "Настройки" необходимого потока данных
- В блоке "Хранилище" переведите переключатель "Постобработка данных" в положение включено.
- Нажмите "Сохранить изменения"
Мониторинг потоков
Мониторинг поступающих событий и метрик
Пользователю доступна функция контроля состояния потоков данных. Если поток не получает данные (логи или метрики) в течении указанного времени, в Журнале ошибок потоков появится соответствующая запись. А также, данным событием об ошибке можно инициировать запуск Бизнес-процесса.
Для включения проверки наличия первичных событий в потоке, выполните следующие действия:
- Перейдите в раздел Сбор (ETL) - Потоки данных через основное меню
- Найдите необходимый поток
- Перейдите на вкладку "Настройки" потока данных
- В блоке Мониторинг активируйте переключатель "Отправлять ошибку в журнал при отсутствии новых данных в потоке более N часов"
По умолчанию для всех потоков данных функция выключена
- Задайте интервал проверки событий в соответствующем поле в часах. Для ввода доступны только целые значения
- Сохраните параметры потока данных
⚠️ Для запуска бизнес-процессов по событиям мониторинга потоков необходимо, чтобы был включен параметр - "пост-обработка данных".
Операции с потоками данных
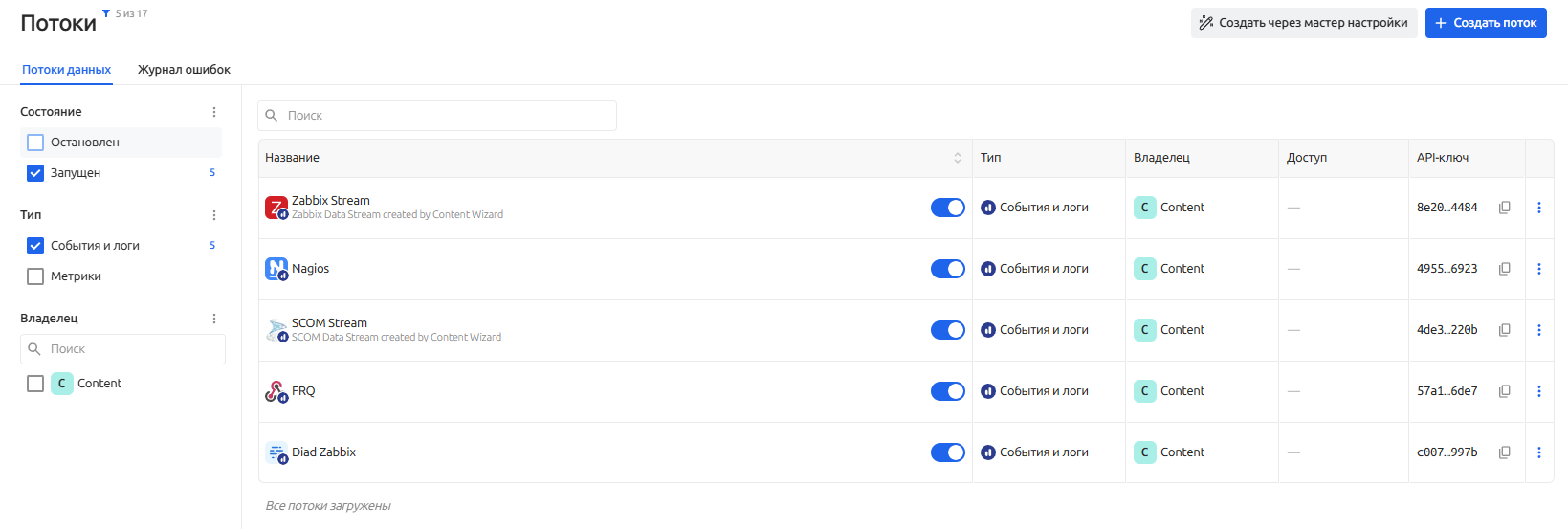
На экране потоков данных представлен общий список потоков с их статусами и типом. Потоки данных можно фильтровать, искать и выполнять различные действия с ними.
Фильтрация потоков данных
Чтобы в списке потоков отобразить только "нужные" потоки данных можно воспользоваться рубрикатором в левой панели списка.
Фильтрация по потокам данных осуществляется по следующим параметрам:
- Состояние
- Остановлен
- Запушен
- Тип
- События и логи
- Метрики
- Владелец
- Рабочая группа, которой принадлежит поток данных (для расшаренных потоков данных)
Настройки фильтра не сохраняются после перехода на другую страницу
Поиск потоков данных
Из множества потоков данных, необходимый вам поток также можно найти, воспользовавшись "Поиском".
- Перейдите в раздел Сбор (ETL) - Потоки данных через основное меню
- В левом верхнем углу в поле Поиск введите текст, поиск будет произведен по следующим параметрам:
- Название
- Описание
- ID
- Владелец
Действия с потоками
Основные операции, которые можно выполнить с выбранным потоком, скрываются в контекстом меню этого потока. Нажмите ︙ напротив необходимого потока данных и выберите необходимое действие:
- Запустить/остановить поток
- Копировать ссылку на поток
- Копировать ID потока
- Копировать API-ключ
- Копировать Webhook URL (только для типа "События и логи")
- Создать копию
- Экспорт
- Перейти к событиям потока или метрикам потока
- Перейти к сборщикам данных
- Удалить
Все, перечисленные операции, также можно выполнить находясь в карточке потока данных.
Настройка доступа к потоку
Пользователь, состоящий в рабочей группе, которой принадлежит поток данных, может предоставить доступ к данным этого потока пользователям других рабочих групп на чтение.
Чтобы предоставить доступ, выполните следующие действия:
- Перейдите в раздел Сбор (ETL) - Потоки данных через основное меню
- Откройте карточку необходимого потока данных
- Нажмите кнопку "Доступ" в правом верхнем углу
- В модальном окне в поле "Выберите Рабочую группу" выберите Рабочие группы, которым необходимо предоставить доступ
- Выдаваемый доступ - только "Просмотр"
- Нажмите Выдать доступ - доступ предоставлен
Статистика потока данных
На вкладке Статистика пользователям доступна информация о собираемых в потоке данных событиях и логах или метриках, в зависимости от типа потока.
Информация представлена в виде гистограмм со статистическими показателями.
Гистограмма по событиям и логам
Гистограмма по Событиям и логам отображает объема данных, полученных через Поток данных, за выбранный промежуток времени со следующими показателями:
- Объем данных за выбранный период
- Средний объем данных за выбранный период = объем данных за период / на количество временных интервалов периода
- Максимальный объем данных за выбранный период = максимальному объему одного из временных интервалов периода
- Минимальный объем данных за выбранный период = минимальному объему одного из временных интервалов периода

Гистограмма по метрикам
Гистограмма по Метрикам отображает количество Метрик, полученных через Поток данных за выбранный промежуток времени со следующими показателями:
- Количество за выбранный период
- Среднее количество за выбранный период = количество за период / на количество временных интервалов периода
- Максимальное количество за выбранный период = максимальному количеству одного из временных интервалов периода
- Минимальное количество за выбранный период = минимальному количеству одного из временных интервалов периода

Экспорт потоков данных
Пользователи системы могут экспортировать настроенные потоки данных в формате base64.
В экспортируемом коде потока данных, содержится следующая информация:
- Вкладка "Настройки"
- Тип
- Иконка
- Обработчик
- Настройки хранения
- Настройки мониторинга
- Пост-обработка данных
Чтобы экспортировать поток данных, находясь на странице списка всех потоков или в карточке выбранного потока, используя дополнительное меню, выберите пункт "Экспорт"
Удаление потока данных
- Перейдите в раздел Сбор (ETL) - Потоки данных через основное меню
- Найдите необходимый поток
- Воспользуйтесь вспомогательным меню ︙ для удаления соответствующего потока данных
При удалении потока будут удалены все данные из хранилища. Данное действие необратимо.
Если удаляемый поток данных был задействован в каком либо сборщике данных - он перейдет в статус ошибки.
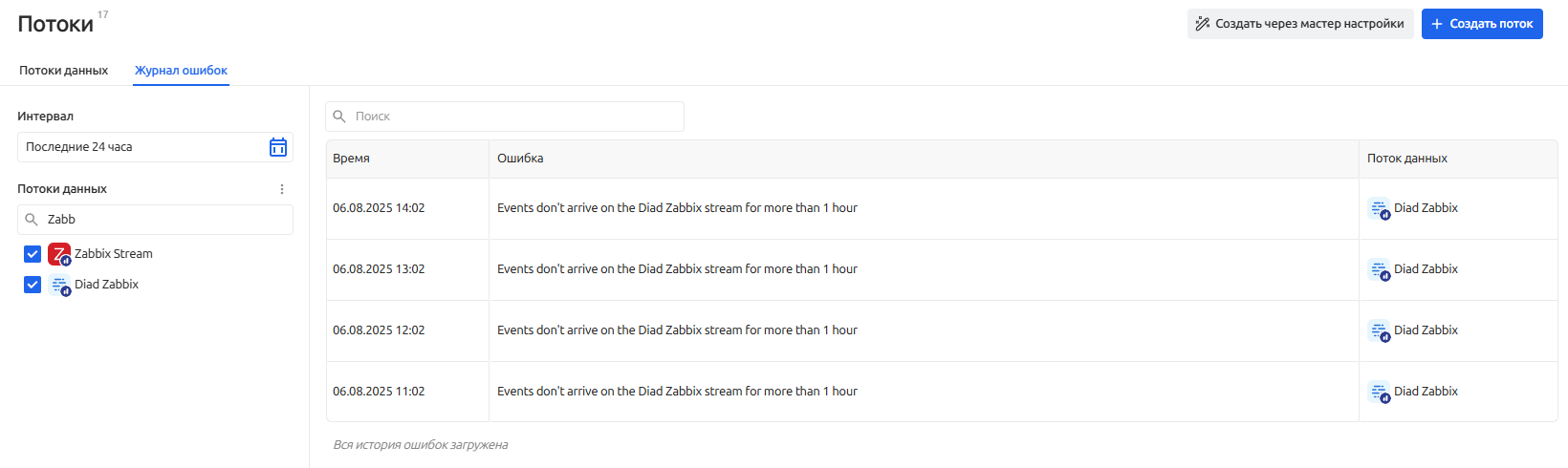
Журнал ошибок
Вкладка "Журнал ошибок" - это инструмент для мониторинга и анализа проблем, возникающих при работе с потоками данных. В нем фиксируются события, которые мешают корректному получению данных, что помогает оперативно реагировать на сбои.
Ошибки попадающие в журнал:
- Ошибки валидации данных - возникают, когда данные не соответствуют ожидаемому формату
- Ошибки работы сценария для обработчика
Automaton - Ошибки связанные с мониторингом потоков
Пример: "Поток настроен на прием JSON, но получил XML или бинарные данные"
В журнале указываются:
- Время ошибки
- Сообщение
- Поток данных