Как оптимизировать сценарии автоматизации для автопостроения карты состояния ИТ-окружения с сотнями тысяч объектов?
Введение
"Берегите песчинки времени — они в конце концов составят горы успеха." (с) Антон Чехов
Можно ли обеспечить в Monq автопостроение карты ИТ-ландшафта крупной компании (или группы компаний) в реальном времени, если у вас:
- более 10 систем-источников с данными о топологии (сервера, сетевые устройства, кассовое оборудование, приложения и пр.);
- больше 1 млн конфигурационных единиц, каждая из которых описывается множеством атрибутов;
- динамический ландшафт: информация о КЕ регулярно изменяется, появляются новые и выводятся из эксплуатации старые КЕ?
Ответ: да, можно, если каждое звено этой цепи будет работать «на максималках» – начиная с проектирования решения (определить модель данных, чтобы забирать только минимально необходимую информацию о КЕ и не «тянуть» лишнюю нагрузку) и разработки производительных плагинов (с использованием всего необходимого арсенала для ускорения работы: оптимизированный код, кэш и т.д.) и заканчивая эффективными сценариями построения CMDB на нашем low code движке автоматизации. Именно о том, как можно оптимизировать эти сценарии, пойдет речь в этой статье.
Обзор стандартных функций
Функции фильтрации КЕ без преувеличения являются «сердцем» сценариев построения топологии. Функции создания КЕ обычно следуют за функциями фильтрации, т.к. правильной логикой будет «сначала проверить существует ли такая КЕ?» и только после этого принимать решение о создании новой КЕ или обновлении существующей.
В зависимости от решаемой задачи можно использовать различные функции движка в своих сценариях:
-
FilterConfigItems (получение доступных КЕ по фильтру);
-
FilterConfigItemsExtended (получение доступных КЕ по фильтру);
-
FilterAttributesConfigItem (получение атрибутов КЕ по фильтру);
-
FilterAttributesConfigItemExpanded (получение атрибутов КЕ по фильтру);
-
GetConfigItem (получение информации о КЕ), если на входе в сценарий в событии уже содержится ID конфигурационной единицы в Monq.
В целом все вышеперечисленные функции работают по одной схеме: функция инициирует запрос к API РСМ -> запрос в БД -> возвращение ответа. Чем больше в БД записей о КЕ и их атрибутах, тем дольше выполняется запрос. В зависимости от реализации сценария удельное время выполнения этой функции может занимать от 10 до 50% времени работы сценария. На больших выборках (более полумиллиона КЕ с множеством атрибутов) это может быть особенно заметно: весь сценарий отработал за 1.5 секунды, из которых фильтрация может занимать до 900-1200 мс. Не всегда такая скорость отвечает требованиям от бизнес-подразделений.
Функция GetConfigItemByUniqueKey
Функция GetConfigItemByUniqueKey в чем-то уникальна и существенно отличается от стандартных функций. Она призвана ускорить обработку сценариев автопостроения ресурсно-сервисных моделей для того, чтобы лаг по времени от поступления события с набором объектов до создания/обновления соответствующих КЕ в системе был минимальным.
Как это работает? На основе ключевых параметров КЕ (как их определить – читайте по ссылке) формируется кэш для быстрого поиска по КЕ данного типа (для каждого экземпляра КЕ генерируется уникальный хэш) и используется в сценариях автоматизации для уменьшения времени ответа при поиске КЕ. Важная особенность: значения уникального атрибута или группы уникальных атрибутов должно быть уникально и не может повторятся у других КЕ этого типа.
Поиск в кэше существенно быстрее поиска в разросшейся БД и соответствующий рост количества КЕ и их атрибутивного состава практически не сказывается на скорости поиска в кэше – в наших замерах функция успевает отрабатывать в диапазоне от 15 до 45 мс (медианное значение – 20 мс).
Пример использования
Для демонстрации отличий в скорости работы двух функций мы выполнили следующие подготовительные работы:
- Развернули тестовую среду на виртуальной машине (запущена в Hyper-V) и установили Monq 7.13.3. Характеристики ВМ:
- 8 cpu (Intel(R) Xeon(R) Platinum 8272CL CPU @ 2.60GHz)
- 32Gb RAM
- 120Gb HDD (SATA)
- Создали новый тип КЕ (“workstation”) и определили его атрибутивный состав, а также назначили один из атрибутов ключевым
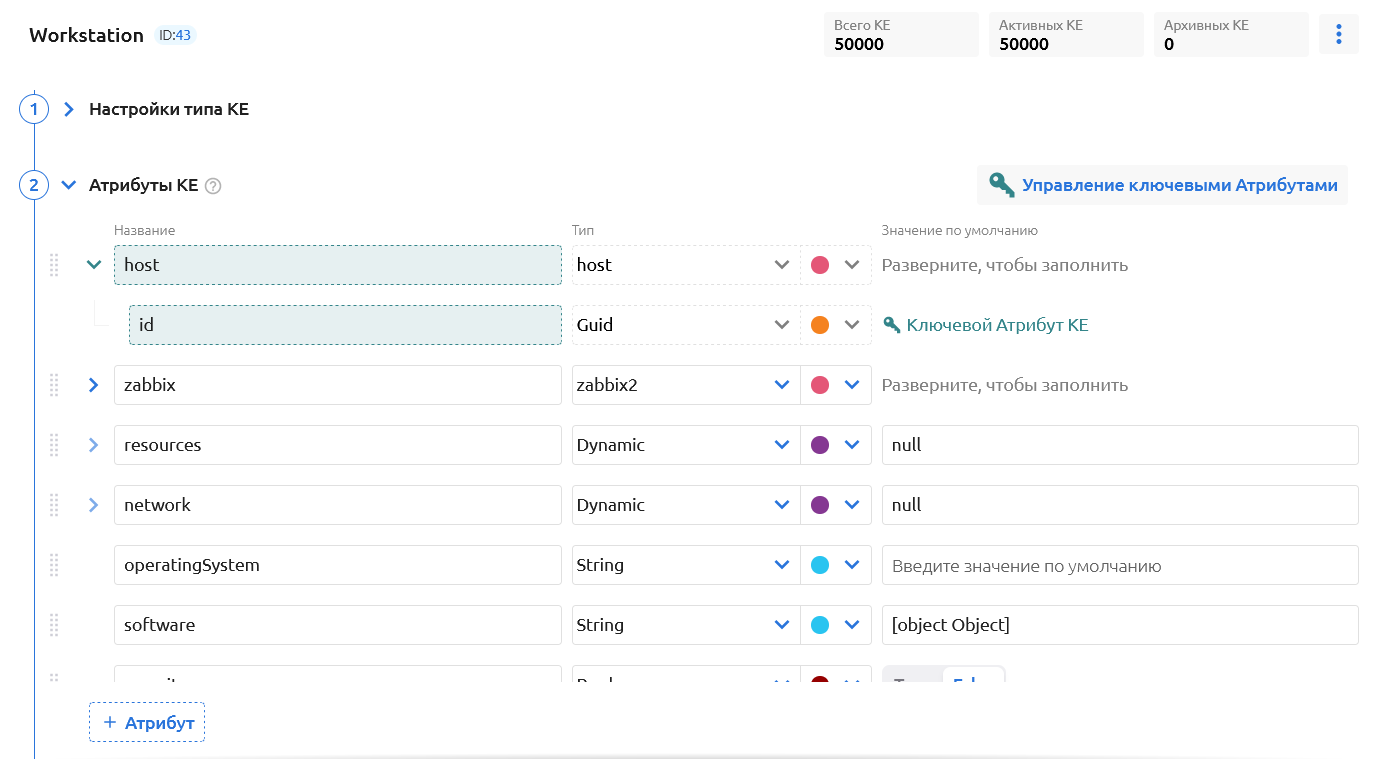
- Создали через API 50 000 КЕ и заполнили их атрибуты различными значениями.
- Написали сценарий обработки события от Zabbix с функцией FilterConfig Items Expand.
- Скопировали сценарий и в копии заменили функцию FilterConfigItemsExpanded на GetConfigItemByUniqueKey – это единственное отличие в двух получившихся сценариях.
Цель испытания: проверить, насколько быстро отработает сценарий создания сигнала и его привязка к КЕ (чтобы привязать сигнал к КЕ, ее сначала надо будет найти в CMDB среди 50 000 экземпляров).
Сценарии мы перевели в режим отладки: это их немного замедляет, но позволяет увидеть время выполнения каждой функции.
Мы провели два типа испытаний:
1. Отправка 50 событий в коллектор 1 раз в секунду – смотрим общее время выполнения сценария и конкретной функции.
Результаты:
-
Общее время выполнения сценария в среднем:
- 59 мс для сценария с поиска по уникальным ключам;
- 148 мс для сценария со стандартной функций фильтрации.
-
Время выполнения функции в среднем:
- 18 мс для GetConfigItemByUniqueKey
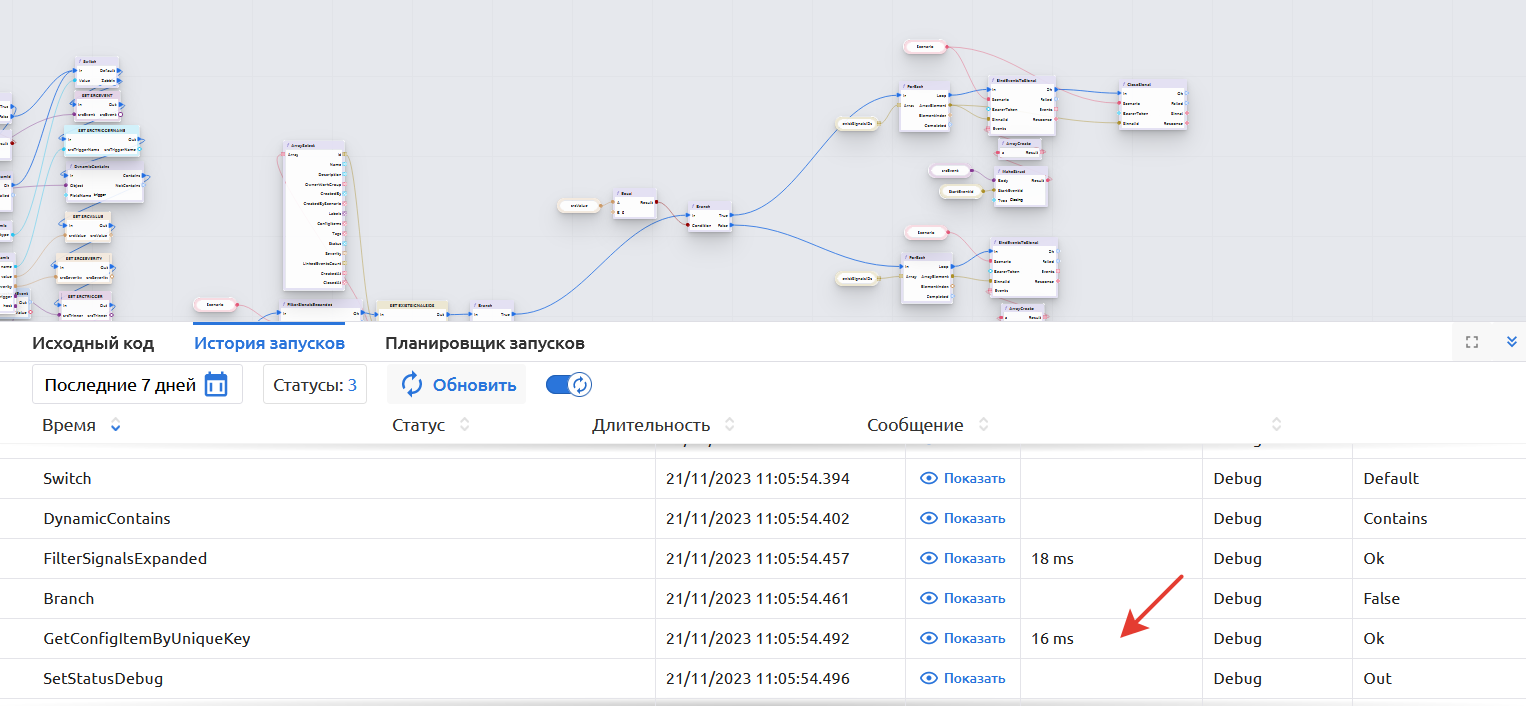
- 58 мс для FilterConfigItemsExpanded
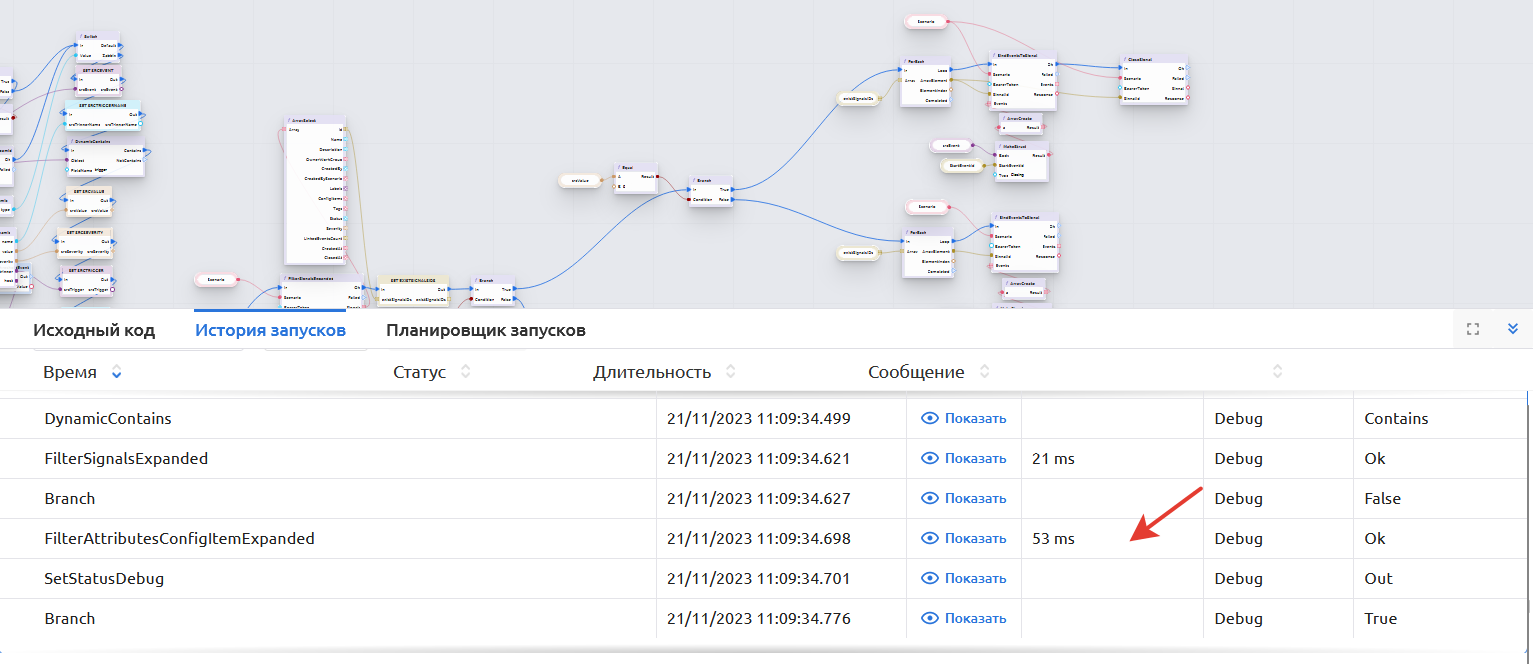
- 18 мс для GetConfigItemByUniqueKey
То есть сама функция на нашем корпусе данных показала скорость выполнения в три раза выше – сценарий с этой функций в составе выполняется в 2.5 раза быстрее и скорость его выполнения сопоставимы с временем выполнения одной только функции фильтрации по КЕ.
2. Отправка через генератор 5000 рандомных событий с задержкой между ними в 50 мс, т.е. около 20 событий/сек. Нам было интересно изучить, как каждым из сценариев будет обработан «шторм» из событий. Результаты:
- Утилизация ресурсов (cpu, memory) в обоих случаях была идентична.
- Интереснее ситуация с временем разбора очереди событий в RabbitMQ:
- Сценарий со стандартной функций фильтрации закончил разбор очереди из 5000 событий за 18,5 мин.
- Сценарий поиска по уникальным ключам закончил разбор аналогичной через 16,5 минут.
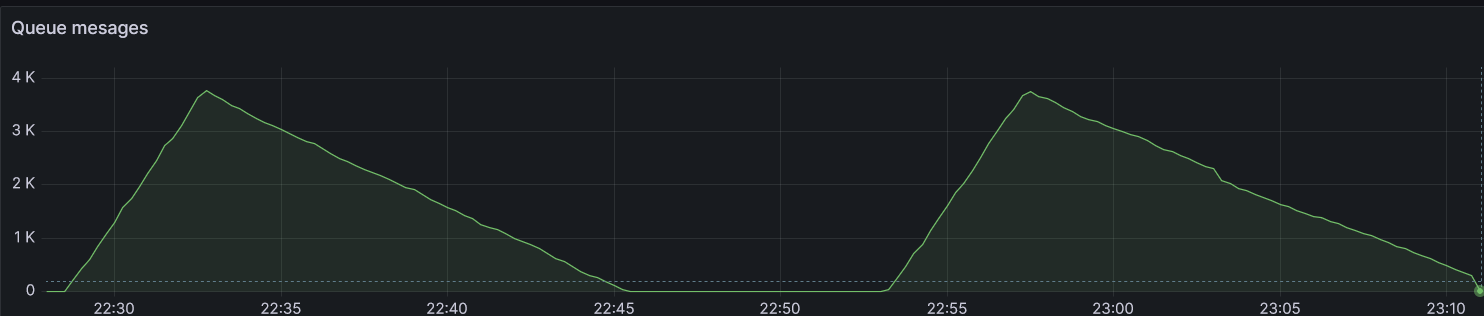
Т.е. скорость разбора очереди заняла на 2 мин меньше (на нашем испытательном стенде мы намеренно оставили минимальное количество раннеров). Это значит, что последнее поступившее событие (инвентарный №: 5000) было обработано только через 14,5 минут и 12,5 минут соответственно.
Заключение
Мы продемонстрировали, каким образом можно ускорить сценарий обработки событий. По аналогии можно оптимизировать и прочие сценарии, предполагающие фильтрацию КЕ, – так одно из звеньев обработки событий станет максимально эффективным. Кроме того, в наших испытаниях мы заметили и другое «слабое» звено: количество запущенных экземпляров раннеров для обработки событий не соответствует тому количеству событий, которые могут генерировать системы мониторинга – на этот момент мы также советуем обращать внимание и при необходимости тюнить конфигурацию под предполагаемое количество событий.
Нужно отметить, что при уменьшении количества КЕ до 10 000 (с сохранением их атрибутивного состава) общая скорость выполнения сценариев с обеими функциями практически сравнялась:
- GetConfigItemByUniqueKey – 18 мс;
- FilterConfigItemsExpanded – 20 мс.
То есть на относительно небольшом количестве КЕ прирост скорости не заметен, и на CMDB таких масштабов использование уникальных атрибутов КЕ и соответствующей функции не имеет смысла.
Также отметим, что обращаться к функции можно и через соответствующий метод публичного API для получения модели какой-либо КЕ.